지난주 AI 컨퍼런스를 다녀왔어요. 전체 세션중에 흥미로웠던 세션이 두개 있었는데 그 중 하나를 공유할까 합니다.
세션의 제목은 “제로 베이스에서 구축해 본 추천 시스템”입니다. 연사자분께서 Udemy의 추천 시스템 작업 경험을 말씀해주시더라구요.
데이터가 없는 상황에서 개인화된 추천 시스템을 구현해야 한다면!
이걸 모두 8개월 내에 만들어야 한다면..!!
제일 먼저 방향성과 현황 파악이 필요했다고 합니다. 이 프로젝트의 목표는 무엇인지, 어떤 지표를 향상 시키고 싶은지, 향후 1~3년간 생각하는 목표는 무엇인지, 현재 DB 현황과 개발 현황은 어떤지.
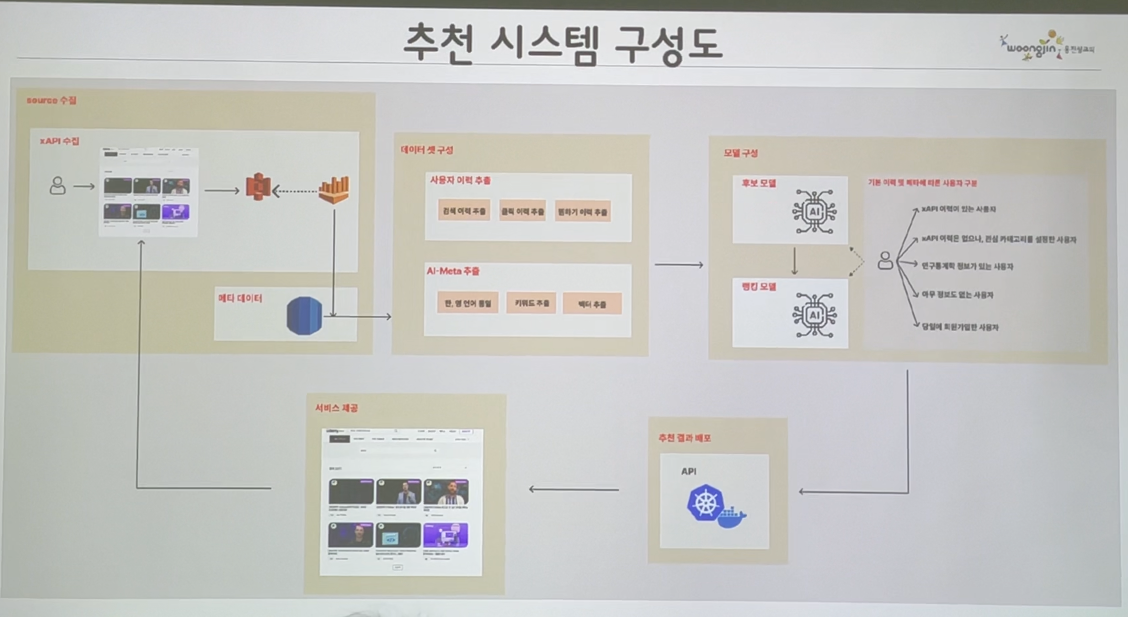
이 Data를 수집 하고 표준화 하는 단계에서 사용했던 API도 말씀해주셨어요. xAPI라는 온라인 학습에서 사용자 경험들을 추적할 수 있는 Experience API를 사용했다고 합니다.
그리고 AI 컨퍼런스에 자주 등장하는 키워드, 정량적인 데이터와 정성적인 데이터 분석! 의도한 방향이 맞는지, ML/DL 분석 관점에서 타당한 데이터를 수집하고 있는지, 서비스 관점에서 활용될 값이 맞는지…
수집된 데이터를 지속적으로 검증하는 과정이 필요한 것 같습니다.
추천 모델 같은 경우엔 여러가지 사례를 비교하면서 염두에 둔건 확장성. Multi-head, Self-Attention과 Shuffling 알고리즘을 연구하셨다고 하는데 이건 솔직히 무슨 얘긴지 모르겠습니다😂
그나마 알아들은 건 Spotify의 Shuffling 알고리즘에서 힌트를 얻기도 했다는 거!!
—
SNS를 구현하다 트위터와 같은 추천 로직을 넣고 싶다는 생각을 했던 적이 있었는데 생각보다 쉬운 일이 아니라는 걸 다시 한번 느끼게 된 것 같아요.